Apollo Client Cache
What's Apollo client cache?
Apollo client cache為Apollo client內建的cache,可以用來儲存一些重要資料,像是歷史的query response。
搭配適當的fetch policy後,對於一些不常變動的資料,我們可以把它存在apollo cache裡面,下次query的時候就不必再去跟server溝通。
Relationship Diagram
- client, cache與server間的交互關係如下:
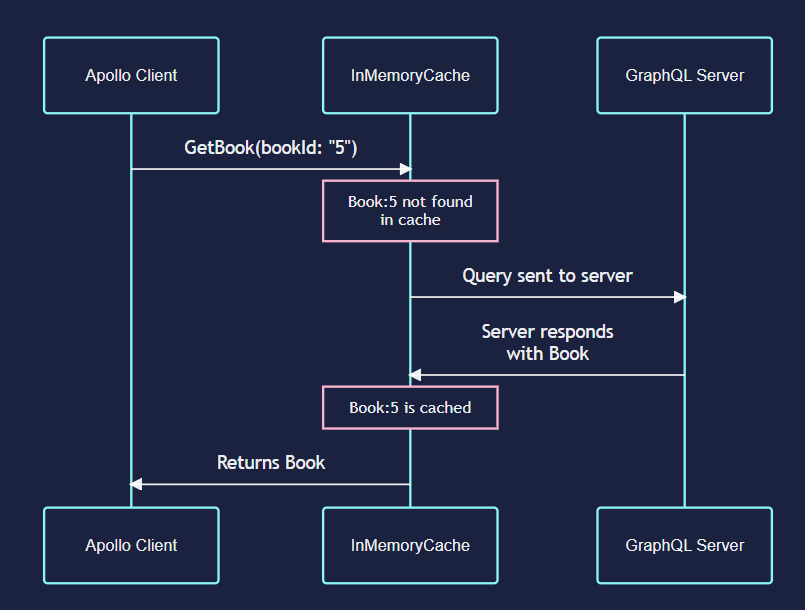
How data stored in cache?
文件提到Apollo cache把資料存成 flat lookup table,可以想成是由多組的key-value pair組合而成的。 因為apollo cache主要用來存取 query response,所以可以把key想成是query本身(包含query 的arguments),而value就是response。
E.g.
- key:
GetBook(bookId: "5") - value:
{ Books: { id: "3", name: "heaven" } }
除此之外,Apollo cache內建還有做一個優化,叫做 data normalization。 做了 data normalization 的好處為: 當程式中有不同query,但response內可能會有重複的object時,可以減少儲存空間。
E.g.
Query 1: Get All Books
- Return
{
data: {
"books": [
{
id: 1,
name: "death"
},
{
id: 2,
name: "heaven"
}
]
}
}Query 2: Get one book that id equals to 2.
- Return
{
data: {
"books": {
id: 2,
name: "heaven"
}
}
}Both queries' response contains
{ Books: { id: "2", name: "heaven" } }.因此,Apollo cache在作完normalization後,儲存格式會變成類似下面這樣結構:
(預設會使用object的id field當作key)
`query1`: [
{
"__ref": "Book:1"
},
{
"__ref": "Book:2"
}
]
`query2`: {
"__ref": "Book:2"
}
而在另外的地方(ROOT)則會存真正的object內容在一個flat lookup table
{
"Book:1" : {
id: "1",
name: "death"
}
},
{
"Book:2" : {
id: "2",
name: "heaven"
}
},
因此當cache讀到 __ref時,就會去ROOT lookup table找到相對應真正的object。這樣在存取相同object時,就避免了存取多個重複object、浪費資源。
Cache Fetch policy
講完了Cache的儲存方式,再來講Cache何時會被讀取。這裡就要提到重要的Fetch policy了
當我們在Query時,可以情境指定不同的fetch policy
cache-first(default policy)- Query先去cache查看是否有完整的資料,若有則立刻回傳。若沒有則再去query graphql server,並把結果更新回cache內。
cache-only- Query只會去cache拿資料。如果cache內沒有完整資料則拋出error。
cache-and-network- 同時去cache跟server拿資料。
- 若cache有資料則先回傳cache的資料
- 接著當server回傳資料後,比對cache內跟server回傳的資料。若有不同則以server的為主,並把結果更新回cache,再回傳client。
network-only- Query先跟server拿資料
- 拿到資料後更新回cache,並回傳給client
no-cache- Query跟server拿資料
- 拿到後直接回傳給client (不存cache)
standby- Query先去cache查看是否有完整的資料,若有則立刻回傳。若沒有則再去query graphql server。
- 與cache-first不同,不會把結果更新回cache內。
Cache behavior
那Apollo client是何時會被讀或是寫入呢?
當然,Apollo client有提供api,可以讓developer在application裡面可以對cache做讀寫等操作。
而為了方便使用,預設行為(Query / Mutation )就會自動對cache去做讀寫了。
- Query
- 若query使用了會存到cache的fetch-policy,則在Query拿到資料後就會把response寫到cache裡面。
- Mutation
- 若Mutation成功後,有回傳完整更新過後的object,則Apollo client會自動把更新後的object寫回cache裡面。
- 更新的預設行為:
- 若舊 object跟新object有重複的field,則以新object為主
- 若舊 object或新object有不重複的field,則保留。
在某些情況下,我們可能需要去客製化資料要如何被存到、寫入cache裡面。
- E.g. Pagination: 我們會希望第一頁的資料跟第二頁的資料都保留住,不會覆蓋彼此。 這時候可以使用Apollo client提供的功能: Field Policy
merge: 指定當寫入cache時該如何存取read: 指定當讀取cache時該如何讀取
E.g. 讀取cache field時,自動轉換成大寫。
const cache = new InMemoryCache({
typePolicies: {
Person: {
fields: {
name: {
read(name) {
// Return the cached name, transformed to upper case
return name.toUpperCase();
}
}
},
},
},
});
E.g. 把新資料跟舊資料的陣列合併 (Pagination)
const cache = new InMemoryCache({
typePolicies: {
Agenda: {
fields: {
tasks: {
merge(existing = [], incoming: any[]) {
return [...existing, ...incoming];
},
},
},
},
},
});
最後關於cache要提的就是 key arguments。 預設行為中,Apollo cache會將每個不同query(包含arguments)視為不同的key。
假設今天想把同一類型的query response都存在同一個cache key裡面,,就必須要指定 key arguments。
E.g. 有個Pagination query,想把